.png "Major AWS Outage Disrupts Global Internet Services on October 20, 2025")
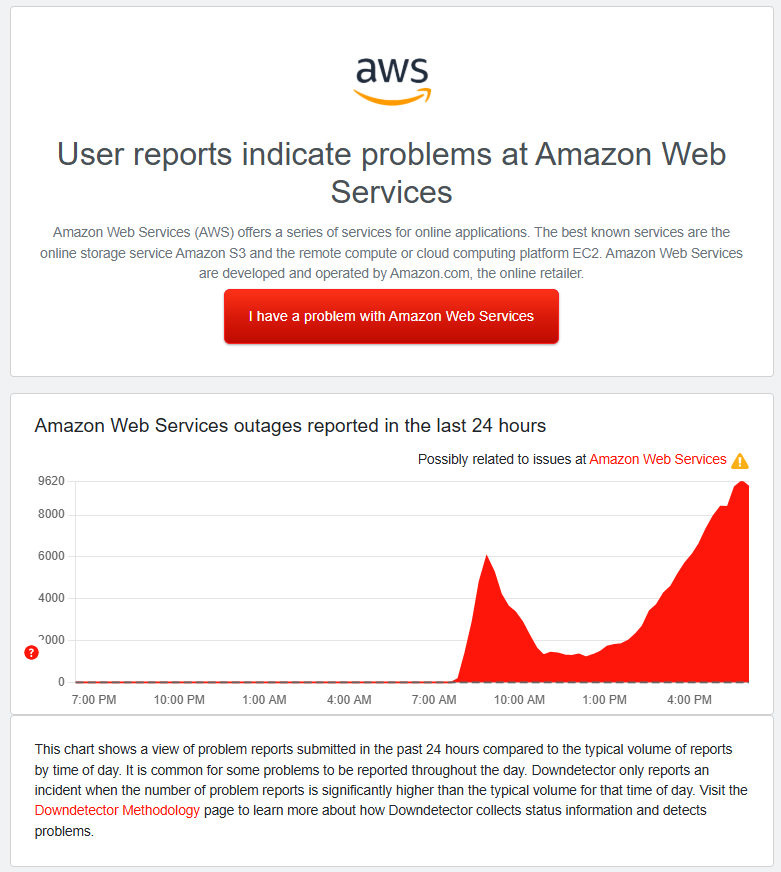
On October 20, 2025, Amazon Web Services (AWS), the world's largest cloud computing provider, experienced a widespread outage that crippled thousands of websites, apps, and services across the internet. The disruption, originating in the US-EAST-1 region in Northern Virginia, highlighted the vulnerabilities in our increasingly cloud-dependent digital infrastructure. Starting shortly after midnight PDT, the incident led to increased error rates, latencies, and connectivity issues, affecting everything from social media platforms to financial services and gaming networks.

The Root Cause and Timeline
According to AWS's Service Health Dashboard, the outage began at approximately 12:11 AM PDT when engineers detected elevated error rates and latencies across multiple services in the US-EAST-1 region. The root cause was quickly identified as a DNS resolution issue with the DynamoDB API endpoint, which cascaded into broader network connectivity problems. This affected not only regional services but also global features reliant on US-EAST-1.
Key updates from AWS included:
- 12:51 AM PDT: Confirmation of significant error rates; mitigation efforts underway.
- 2:01 AM PDT: Potential root cause linked to DNS issues; multiple mitigation strategies pursued.
- 3:35 AM PDT: DNS problem mitigated, with recovery observed in most services, though backlogs and throttling persisted.
- 7:29 AM PDT (latest update): Network connectivity issues confirmed, with early signs of recovery but ongoing root cause investigation.
By mid-afternoon, AWS reported that most services were recovering, but lingering issues remained for tasks like new EC2 instance launches and event processing backlogs in services such as CloudTrail and EventBridge. The outage lasted over three hours for full initial resolution, with some impacts extending into the day.
Widespread Impacts on Services and Businesses
The outage's ripple effects were felt globally, as AWS powers a significant portion of the internet. Over 2,000 companies reported disruptions, including major players in social media, finance, gaming, and more. Websites and apps went offline or experienced severe slowdowns, demonstrating how a single region's failure can cascade worldwide.
Here’s a breakdown of some key affected sectors and examples:
| Sector | Affected Services/Companies | Reported Issues |
|---|---|---|
| Social Media & Communication | Reddit, Snapchat, Signal, Slack, Pinterest | Outages, login failures, message delivery delays. |
| Gaming & Entertainment | Roblox, Fortnite | Server downtime, inability to connect to games. |
| Finance & Trading | Coinbase, Robinhood, Venmo | Trading halts, app crashes, transaction errors. |
| Home & Security | Ring (doorbells) | Service disruptions, video feed issues. |
| Education & Productivity | Canvas, Zoom, Grammarly, Duolingo | Interrupted online classes, tool unavailability. |
| Airlines & Travel | Delta Air Lines, United Airlines | Booking and check-in system glitches. |
Additionally, AWS internal services saw impairments: 78 services were impacted, including Lambda, EC2, DynamoDB, RDS, and ECS, while 33 had recovered by the latest reports. Users were advised to retry failed requests, avoid specific Availability Zones for launches, and flush DNS caches.
Broader Implications and Expert Reactions
This incident underscores the risks of over-reliance on a few dominant cloud providers like AWS, Microsoft Azure, and Google Cloud. Experts noted similarities to past disruptions, such as the 2024 CrowdStrike outage, emphasizing the need for better redundancy and multi-cloud strategies.
Nicky Stewart, Senior Advisor at the Open Cloud Coalition, called it a "visceral reminder" of these risks, suggesting it could accelerate demands for regional cloud sovereignty. In Europe, the outage prompted discussions on digital resilience, with one official describing it as a matter of "security and resilience."
Financially, AWS represents about 20% of Amazon's sales but 60% of its operating profit, yet the company's stock showed minimal movement, indicating investor confidence in quick recovery.
Looking Ahead
As AWS continues mitigation efforts, full recovery is expected soon, but the event serves as a wake-up call for businesses to diversify their cloud dependencies. For real-time updates, users should monitor the AWS Service Health Dashboard. This outage, while resolved relatively quickly, reminds us of the interconnected—and fragile—nature of the modern web.
